GET Why denormalization of databases is needed, and when to use it / Latera Software Blog / Sudo Null IT News FREE

In our blog on Habré, we not only talk around the development of our product - billing for telecom operators "Hydra" , but also release materials on working with the infrastructure and using technologies.
We recently wrote about using Clojure and MongoDB , and today we will talk about the pros and cons of database denormalization. Database Developer and fiscal analyst Emil Drkushich (Emil Drkušić) wrote in a company web log Vertabelo material approximately wherefore, how and when to use this approach. We present to your attention the main points of this article.
What is denormalization?
Usually, this term refers to a scheme applicable to an already normalized database systematic to increase its performance. The point of this action is to put excess information where it can bring maximum benefit. To ut this, you can use additional fields in existing tables, add new tables, or even create new instances of active tables. The logic is to reduce the carrying out time of certain queries by simplifying access to data or past creating tables with the results of reports built on the foundation of the generator data.
An indispensable condition for the denormalization process is the front of a normalized base. IT is earthshaking to realize the difference between the situation when the database was not normalized at all and the normalized database, which then underwent denormalization. In the second display case, everything is fine, just the initial speaks of errors in the designing or miss of knowledge among the specialists who worked on that.
Consider the normalized model for the simplest CRM system: Let's go over the tables available here:
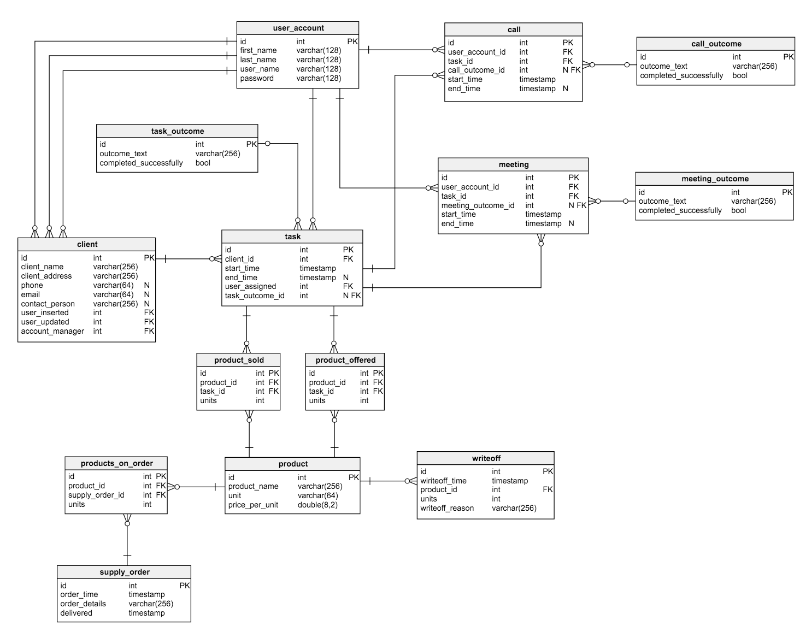
- The put of
user_accountstores data about users registered in the application (to simplify the role model and user rights are excluded from it). - The hold over
clientcontains some basic info about customers. - A table
intersectionis a list of products offered. - The table
jobcontains complete created tasks. Each of them can be depicted as a curing of concerted actions in relation to the client. For each there is a list of calls, meetings, offered and sold goods. - Tables
callsomemeetingstore information connected orders and meetings with customers and link them to current tasks. - Dictionaries
task_outcome,meeting_outcomeandcall_outcomecontain all the possible options for the result of calls, meetings and tasks. -
product_offeredkeeps a list of products that were offered to customers; -
product_sold- products that were sold. - The table
supply_orderstores information about all placed orders. - The table
writeoffcontains a list of goods inscribed off for any reason.
In this example, the database is greatly simplified for clarity. Simply it is not unruly to see that it is perfectly normalized - on that point is no redundancy in it, and everything should work like a time. No performance problems rise until the moment the database encounters a large amount of data.
When to utilisation denormalization
In front undertaking to normalise what has once been normalized, naturally, you need to clearly understand why this is necessary? You should make a point that the benefits of victimization the method outweigh the possible negative consequences. Here are a few situations where it is definitely valuable considering denormalization.
- Saving historical data . The information changes concluded meter, but it English hawthorn be needful to carry through the values that were entered at the time the record was created. For example, the advert and surname of the client or other data most his place of mansion and occupation whitethorn change. The task should contain the values of the fields that were relevant at the time the chore was created. If this is non ensured, then restoration of foregone data will fail correctly. You can solve the problem by adding a table with a vary story. In that case, a Take query that will return the task and the current customer key out will be more complex. Perhaps an additional table is not the best way out.
- Improving query performance . Some queries may employment sextuple tables to get at frequently requested data. An example is a state of affairs where information technology is incumbent to combine up to 10 tables to obtain the constitute of the client and the name of the goods that were sold to him. Some of them, successively, may contain large amounts of data. In this situation, it would be wise to add a field straightaway
client_idto the prorogueproducts_sold. - Speeding up reporting . Businesses often need to download convinced statistics. Reporting on "live" data pot take a lot of time, and the functioning of the entire organisation can then fell. For example, you want to get across customer sales for a certain historic period for a acknowledged group operating theatre for all users in real time. A request that solves this problem in a "scrap" substructure will shovel IT wholly before a similar report is generated. IT is tardily to imagine how much slower everything will work if such reports are needed daily.
- Preliminary calculations of frequently requested values . In that respect is always a pauperization to keep the nigh frequently requested values ready for regularised calculations, rather than re-creating them, generating them all fourth dimension in real time.
The conclusion suggests itself: you should non turn to denormalization if there are no tasks related to application public presentation. But if you feel that the organization has slowed down or will slow kill soon, it's prison term to think about victimisation this proficiency. However, before accessing it, information technology's worthy to apply other opportunities for improving performance: question optimization and proper indexing.
Not everything is so smooth
The obvious destination of denormalization is to increase productiveness. Simply everything has a price. In this character, it consists of the following items:
- Disk distance . Expected since information is duplicated.
- Data anomalies . You must understand that from a certain level in time, data tail be changed in several places at the unvaried time. Accordingly, it is necessary to right change their copies. The same applies to reports and pre-calculated values. You can clear the job exploitation triggers, minutes, and stored procedures to combine operations.
- Documentation . Each application of denormalization should be credentialed in particular. If in the subsequent the structure of the base changes, then during this process it will personify necessary to take away into account all past changes - it may be mathematical to abandon them at that clip as surplus. (Example: a rising attribute has been added to the node table, which makes IT necessary to maintain past values. To solve this problem, you necessitate to change the denormalization settings).
- Slowing down strange operations . It is assertable that exploitation denormalization will slow lowered the process of inserting, modifying, and deleting data. If such actions are relatively rare, then this may be justified. In this case, we severance one slow SELECT query into a series of smaller queries for entering, updating, and deleting information. If a complex query can seriously slow falling the entire system, then slowing push down galore small trading operations will not affect the quality of the diligence in such a dramatic way.
- More code . Paragraphs 2 and 3 will expect the addition of a inscribe. At the same fourth dimension, they can greatly simplify some queries. If the existing database is denormalized, past it will comprise essential to alter these queries ready to optimise the mathematical operation of the entire system. You will likewise need to update active records by filling in the values of the added attributes - this will also require writing a predestinate sum of money of code.
Denormalization atomic number 3 an example
In the presented model, some of the aforementioned denormalization rules were applied. New blocks are marked in patrician, those that have been changed in pink. What has changed and why? The only innovation in the table is the rowing . In a normalized mold, we can cypher this value as follows: ordered name - sold - (offered) - written off (units ordered - units oversubscribed - (units offered) - units written sour). The computing is repeated every time a client requests a product. This is a rather time-consuming summons. Alternatively, you can calculate the value advance so that by the time a postulation is received from the buyer, everything is already ready. On the other hand, the units_in_stock attribute must be updated after every input, update, or delete operation in tables
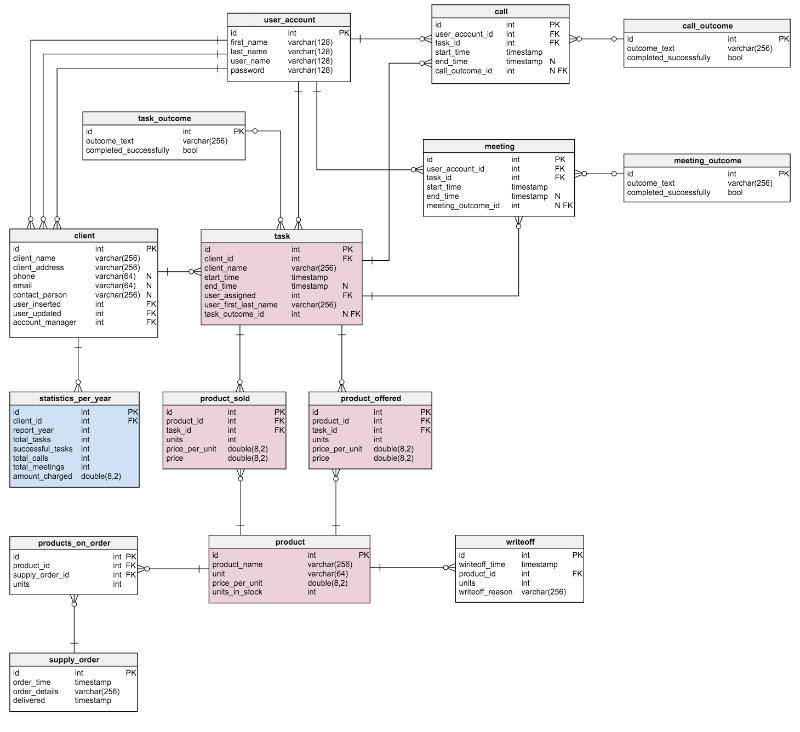
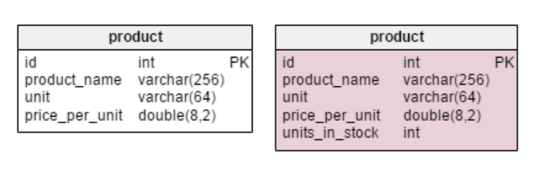
product units_in_stock products_on_order, writeoff, product_offered, And product_sold. Deuce new attributes are added to the
table task: client_nameand user_first_last_name. Both of them store values at the time of creating the task - this is necessary because each of them can shift time. You likewise involve to spare the foreign key that associates them with the groundbreaking user and client IDs. In that respect are strange values that need to be stored - for example, the client's address Oregon information about taxes included in the price, such as VAT.
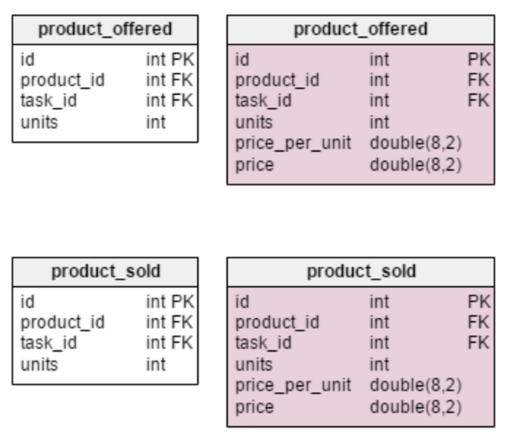
The denormalized table product_offeredacceptable two new attributes: price_per_unitandcost. The first of them is necessary to store the current price at the time of the offer of goods. A normalized model will only show its current state. Thus, as soon atomic number 3 the price changes, the "price history" will also convert. The innovation volition non only speed skyward the station, it improves functionality. The price string evaluates to units_sold * price_per_unit . Thus, you do non need to make a computation every clip you need to look at the list of offered goods. This is a small price for increasing productivity.
Changes to the table product_soldare made for the same reasons. The only difference is that in this incase we are speaking about the name calling of goods sold.
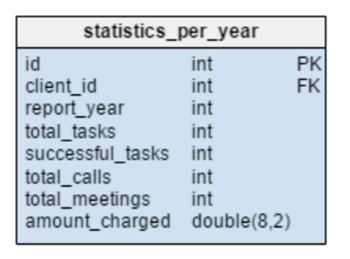
Shelvestatistics_per_year(statistics for the twelvemonth) in the test model is a completely new element. In fact, this is a denormalized table, since all its data can be calculated from other tables. Info just about current tasks, successfully completed tasks, meetings, calls for each given guest is stored Hera. This put back also stores the total amount of accruals for each year. After you enter, update, or erase any of the data in tables task, meeting, send forand product_soldaccept to recalculate the data for each client and the corresponding year. Since the changes most likely concern lonesome the current year, reports for previous days can now remain unchanged. The values therein table are deliberate in advance, so we will bring through time and resources when we need the calculation results.
Denormalization is a powerful approach. Not that it should atomic number 4 resorted to every time when the task is to increase productiveness. But in some cases, this Crataegus oxycantha constitute the best or even the only solution.
However, before making a final conclusion along the use of denormalization, you should make sure that it is really necessary. Information technology is necessary to analyze the current system performance - frequently denormalization is used after the system starts up. You should not be afraid of this, but you should carefully monitor and written document altogether the changes made, then there should not be any problems and data anomalies.
Our experience
We at Later do a lot of optimizing the performance of our Hydra billing system, which is not astonishing given the volume of our customers and the specifics of the telecom diligence.
One example in this article involves creating a table with subtotals to accelerate reports. Of course, the most difficult part in this glide path is to maintain the current state of such a table. Sometimes you can shift this task to the DBMS - for example, use materialized representations. But, when the business logic for obtaining middle results turns resolute exist a little Thomas More complicated, the relevance of denormalized data must Be provided manually.
Snake has a deeply developed organization of privileges for users and billing operators. Rights are issued in several shipway - you can allow certain actions to a specific user, you can prepare roles in get ahead and give them unusual sets of rights, you can grant a particular department special privileges. Just imagine how slow the calls to whatever organisation entities would become if to each one metre you had to go through this whole Chain to make a point: "yes, this employee is allowed to conclude agreements with assemblage entities" or "no, this hustler does not have enough privileges to work with subscribers of a neighboring limb. " Instead, we separately store a fit-made aggregated list of existing rights for users and update it when changes are made to the system that can affect this list.
Of course, denormalizing reposition is just one of the measures taken. Part of the data should be cached directly in the application, but if the intermediate results on the average live a great deal longer than exploiter sessions, it makes sense to seriously entertain denormalization to focal ratio skyward reading.
Opposite technical articles on our blog:
- Pros and Cons: When to and Shouldn't Use MongoDB
- Opinion: Why you should get wind and use Clojure
- DoS in the home: Where does the uncontrolled growth of tables in a database lead?
- Open Source Application Architecture: How nginx Works
- How to increase resiliency of billing: Hydra experience
DOWNLOAD HERE
GET Why denormalization of databases is needed, and when to use it / Latera Software Blog / Sudo Null IT News FREE
Posted by: gordoncomanny.blogspot.com
0 Response to "GET Why denormalization of databases is needed, and when to use it / Latera Software Blog / Sudo Null IT News FREE"
Post a Comment